
Hardware Configuration Reference Guide
- Overview
- OmniSciDB Architecture
- Hot Records and Columns
- Projection-Only Columns
- CPU RAM
- SSD Storage
- Hardware Sizing Schedule
- CPU Cores
- PCIe
- NVLink
- System Examples
Overview
The amount of data you can process with the OmniSci database depends primarily on the amount of GPU RAM and CPU RAM available across OmniSci cluster servers. For zero-latency queries, the system caches compressed versions of the row- and column-queried fields into GPU RAM. This is called hot data (see Hot Records and Columns). Semi-hot data utilizes CPU RAM for certain parts of the data.
System Examples shows example configurations to help you configure your system.

Optimal GPUs on which to run the OmniSci Platform include:
- NVIDIA Tesla V100 v2
- NVIDIA Tesla V100 v1
- NVIDIA Tesla K80
- NVIDIA Tesla P100
- NVIDIA Tesla P40
The following configurations are valid for systems using any of these GPUs as the building blocks of your system. For production systems, use Tesla enterprise-grade cards. Avoid mixing card types in the same system; use a consistent card model across your environment.
Primary factors to consider when choosing GPU cards are:
- The amount of GPU RAM available on each card
- The number of GPU cores
- Memory bandwidth
Newer cards like the Tesla V100 have higher double-precision compute performance, which is important in geospatial analytics. The Tesla V100 models support the NVLink interconnect, which can provide a significant speed increase for some query workloads.
| GPU | Memory/GPU | Cores | Memory Bandwidth | NVLink |
|---|---|---|---|---|
| Tesla V100 v2 | 32 GB | 5120 | 900 GB/sec | Yes |
| Tesla V100 | 16 GB | 5120 | 900 GB/sec | Yes |
| P100 | 16 GB | 3584 | 732 GB/sec | Yes |
| P40 | 24GB | 3840 | 346 GB/sec | No |
| K80 | 24GB | 4992 | 480 GB/sec | No |
For advice on optimal GPU hardware for your particular use case, ask your OmniSci sales representative.
OmniSciDB Architecture
Before considering hardware details, this topic describes the OmniSciDB architecture.
OmniSciDB is a hybrid compute architecture that utilizes GPU, CPU, and storage. GPU and CPU are the Compute Layer, and SSD storage is the Storage Layer.
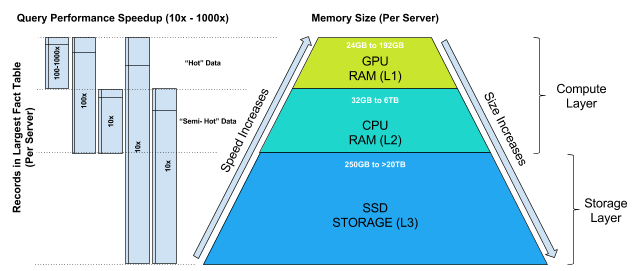
When determining the optimal hardware, make sure to consider the storage and compute layers separately.
Loading raw data into OmniSciDB ingests data onto disk, so you can load as much data as you have disk space available, allowing some overhead.
When queries are executed, OmniSciDB optimizer utilizes GPU RAM first if it is available. You can view GPU RAM as an L1 cache conceptually similar to modern CPU architectures. OmniSciDB attempts to cache the hot data. If GPU RAM is unavailable or filled, OmniSciDB optimizer utilizes CPU RAM (L2). If both L1 and L2 are filled, query records overflow to disk (L3). To minimize latency, use SSDs for the Storage Layer.
You can run a query on a record set that spans both GPU RAM and CPU RAM as shown in the diagram above, which also shows the relative performance improvement you can expect based on whether the records all fit into L1, a mix of L1 and L2, only L2, or some combination of L1, L2, and L3.
Hot Records and Columns
The Hardware Sizing Schedule table refers to hot records, which are the number of records that you want to put into GPU RAM to get zero-lag performance when querying and interacting with the data. The Hardware Sizing Schedule assumes 16 hot columns, which is the number of columns involved in the predicate or computed projections (such as, column1 / column2) of any one of your queries. A 15 percent GPU RAM overhead is reserved for rendering buffering and intermediate results. If your queries involve more columns, the number of records you can put in GPU RAM decreases, accordingly.
| Important | The server is not limited to any number of hot records. You can store as much data on disk as you want. The system can also store and query records in CPU RAM, but with higher latency. The hot records represent the number of records on which you can perform zero-latency queries. |
Projection-only Columns
OmniSciDB does not require all queried columns to be processed on the GPU. Non-aggregate projection columns, such as
SELECT x, y FROM table, do not need to be processed on the GPU, so can be stored in CPU RAM. The Hardware Sizing Schedule CPU RAM
sizing assumes that up to 24 columns are used in only non-computed projections, in addition to the Hot Records and Columns.
CPU RAM
The amount of CPU RAM should equal four to eight times the amount of total available GPU memory. Each NVIDIA Tesla P40 has
24 GB of onboard RAM available, so if you determine that your application requires four NVIDIA P40 cards, you need between
4 x 24 GB x 4 (384 GB) and 4 x 24 GB x 8 (768 GB) of CPU RAM. This correlation between GPU RAM and CPU RAM exists because the
OmniSci database uses CPU RAM in certain operations for columns that are not filtered or aggregated.
SSD Storage
An OmniSci deployment should be provisioned with enough SSD storage to reliably store the required data on disk, both in compressed format and in OmniSci itself. OmniSci requires 30% overhead beyond compressed data volumes. OmniSci recommends drives such as the Intel® SSD DC S3610 Series, or similar, in any size that meets your requirements.
| Notes |
|
Hardware Sizing Schedule
This schedule estimates the number of records you can process based on GPU RAM and CPU RAM sizes, assuming up to 16 hot columns (see Hot Records and Columns). This applies to the compute layer. For the storage layer, provision your application according to SSD Storage guidelines.
| GPU Count | GPU RAM (GB) | CPU RAM (GB) | “Hot” Records |
|---|---|---|---|
| (NVIDIA P40) | 8x GPU RAM | L1 | |
| 1 | 24 | 192 | 417M |
| 2 | 48 | 384 | 834M |
| 3 | 72 | 576 | 1.25B |
| 4 | 96 | 768 | 1.67B |
| 5 | 120 | 960 | 2.09B |
| 6 | 144 | 1,152 | 2.50B |
| 7 | 168 | 1,344 | 2.92B |
| 8 | 192 | 1,536 | 3.33B |
| 12 | 288 | 2,304 | 5.00B |
| 16 | 384 | 3,456 | 6.67B |
| 20 | 480 | 3,840 | 8.34B |
| 24 | 576 | 4,608 | 10.01B |
| 28 | 672 | 5,376 | 11.68B |
| 32 | 768 | 6,144 | 13.34B |
| 40 | 960 | 7,680 | 16.68B |
| 48 | 1,152 | 9,216 | 20.02B |
| 56 | 1,344 | 10,752 | 23.35B |
| 64 | 1,536 | 12,288 | 26.69B |
| 128 | 3,072 | 24,576 | 53.38B |
| 256 | 6,144 | 49,152 | 106.68B |
If you already have your data in a database, you can look at the largest fact table, get a count of those records, and compare that with this schedule.
If you have a .csv file, you need to get a count of the number of lines and compare it with this schedule.
CPU Cores
OmniSci uses the CPU in addition to the GPU for some database operations. GPUs are the primary performance driver; CPUs are utilized secondarily. More cores provide better performance but increase the cost. Intel CPUs with 10 cores offer good performance for the price. For example, so you could configure your system with a single NVIDIA P40 GPU and two 10-core CPUs. Similarly, you can configure a server with eight P40s and two 10-core CPUs.
Suggested CPUs:
- Intel® Xeon® E5-2650 v3 2.3GHz, 10 cores
- Intel® Xeon® E5-2660 v3 2.6GHz, 10 cores
- Intel® Xeon® E5-2687 v3 3.1GHz, 10 cores
- Intel® Xeon® E5-2667 v3 3.2GHz, 8 cores
PCI Express (PCIe)
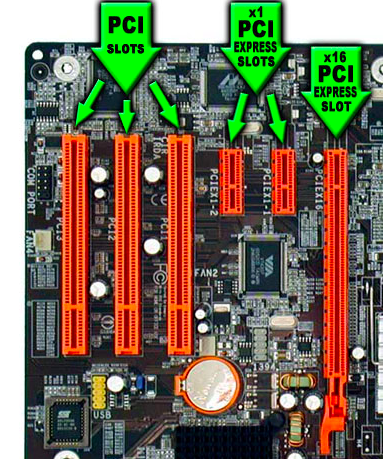
GPUs are typically connected to the motherboard using PCIe slots. The PCIe connection is based on the concept of a lane, which is a single-bit, full-duplex, high-speed serial communication channel. The most common numbers of lanes are x4, x8, and x16. The current PCIe 3.0 version with a x16 connection has a bandwidth of 16 GB/s. PCIe 2.0 bandwidth is half the PCIe 3.0 bandwidth, and PCIe 1.0 is half the PCIe 2.0 bandwidth. Use a motherboard that supports the highest bandwidth, preferably, PCIe 3.0. To achieve maximum performance, the GPU and the PCIe controller should have the same version number.
The PCIe specification permits slots with different physical sizes, depending on the number of lanes connected to the slot. For example, a slot with an x1 connection uses a smaller slot, saving space on the motherboard. However, bigger slots can actually have fewer lanes than their physical designation. For example, motherboards can have x16 slots connected to x8, x4, or even x1 lanes. With bigger slots, check to see if their physical sizes correspond to the number of lanes. Additionally, some slots downgrade speeds when lanes are shared. This occurs most commonly on motherboards with two or more x16 slots. Some motherboards have only 16 lanes connecting the first two x16 slots to the PCIe controller. This means that when you install a single GPU, it has the full x16 bandwidth available, but two installed GPUs each have x8 bandwidth.
OmniSci recommends installing GPUs in motherboards with support for as much PCIe bandwidth as possible. On modern Intel chip sets, each socket (CPU) offers 40 lanes, so with the correct motherboards, each GPU can receive x8 of bandwidth. All recommended System Examples have motherboards designed for maximizing PCIe bandwidth to the GPUs.
OmniSci does not recommend adding GPUs to a system that is not certified to support the cards. For example, to run eight GPU cards in a machine, the BIOS register the additional address space required for the number of cards. Other considerations include power routing, power supply rating, and air movement through the chassis and cards for temperature control.
For an emerging alternative to PCIe, see NVLink.
NVLink
NVLink is a new bus technology developed by Nvidia. Compared to PCIe, NVLink offers higher bandwidth between host CPU and GPU and between the GPU processors. NVLink-enabled servers, such as the IBM S822LC Minsky server, can provide up to 160 GB/sec bidirectional bandwidth to the GPUs, a significant increase over PCIe. Because Intel does not currently support NVLink, the technology is available only on IBM Power servers. Servers like the NVIDIA-manufactured DGX-1 offer NVLink between the GPUs but not between the host and the GPUs.
System Examples
A variety of hardware manufacturers make suitable GPU systems. For more information, follow these links to their product specifications.